In the era of distributed systems, microservices are hailed for their scalability, resilience, and modularity. However, this architectural freedom comes with a hidden cost—API latency.
A seemingly insignificant delay in one service can propagate and amplify through an entire request chain, degrading the user experience.
What Is API Latency?
API latency is the time it takes from when a client sends a request to when it receives a response. This includes:
- Network latency (transmission time)
- Queueing delay (waiting for a thread)
- Processing time (backend logic)
- Dependency delay (downstream service calls)
Microservices and the Domino Effect
In microservice architectures, a single user request often triggers multiple downstream API calls across different services.
A 300ms delay in Service A might not seem problematic—until you realize it’s called 20 times per transaction.
Example: Chained Latency in an E-commerce App
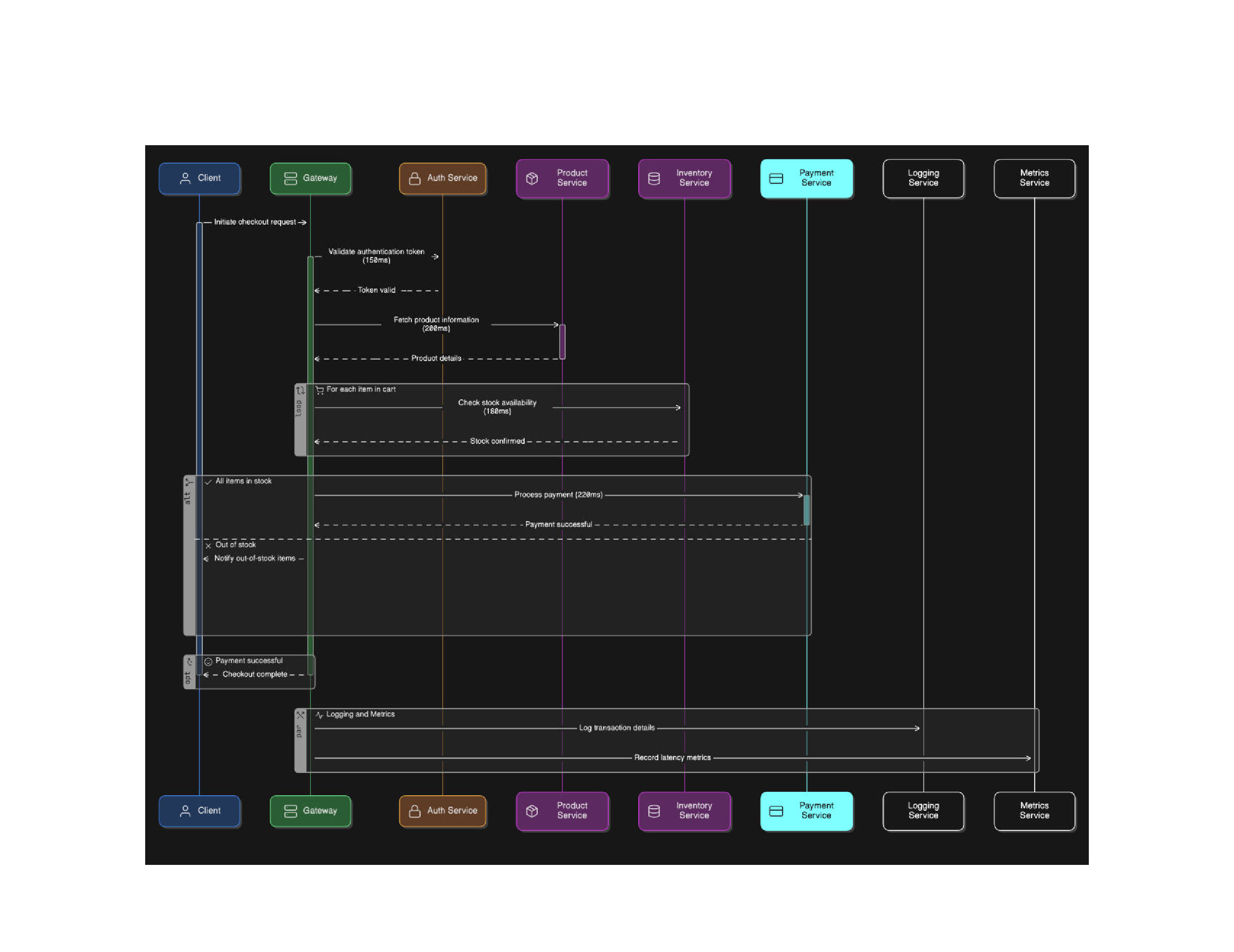
$\text{Total Latency} = 150 + 200 + 180 + 220 = 750,\text{ms}$
And this doesn’t include the Gateway’s own processing or retry overheads!
Compounding Latency: The N+1 Problem
Sometimes, services don’t just call one downstream API—they call many, often in loops or dynamically.
Example:
# N+1 API problem in pseudocode
for product_id in cart:
stock_info = call_inventory_service(product_id)
Calling 10 products individually instead of batching can cause latency to skyrocket.
Tools to Detect Latency Bottlenecks
- Distributed Tracing – Tools like Jaeger, Zipkin, or OpenTelemetry can trace API paths and identify where time is spent.
- APM Platforms – Datadog, New Relic, Dynatrace visualize latency hotspots in real-time. Custom Metrics – Log latency by endpoint and status to surface slow interactions.
Visual: Latency Breakdown Across Services
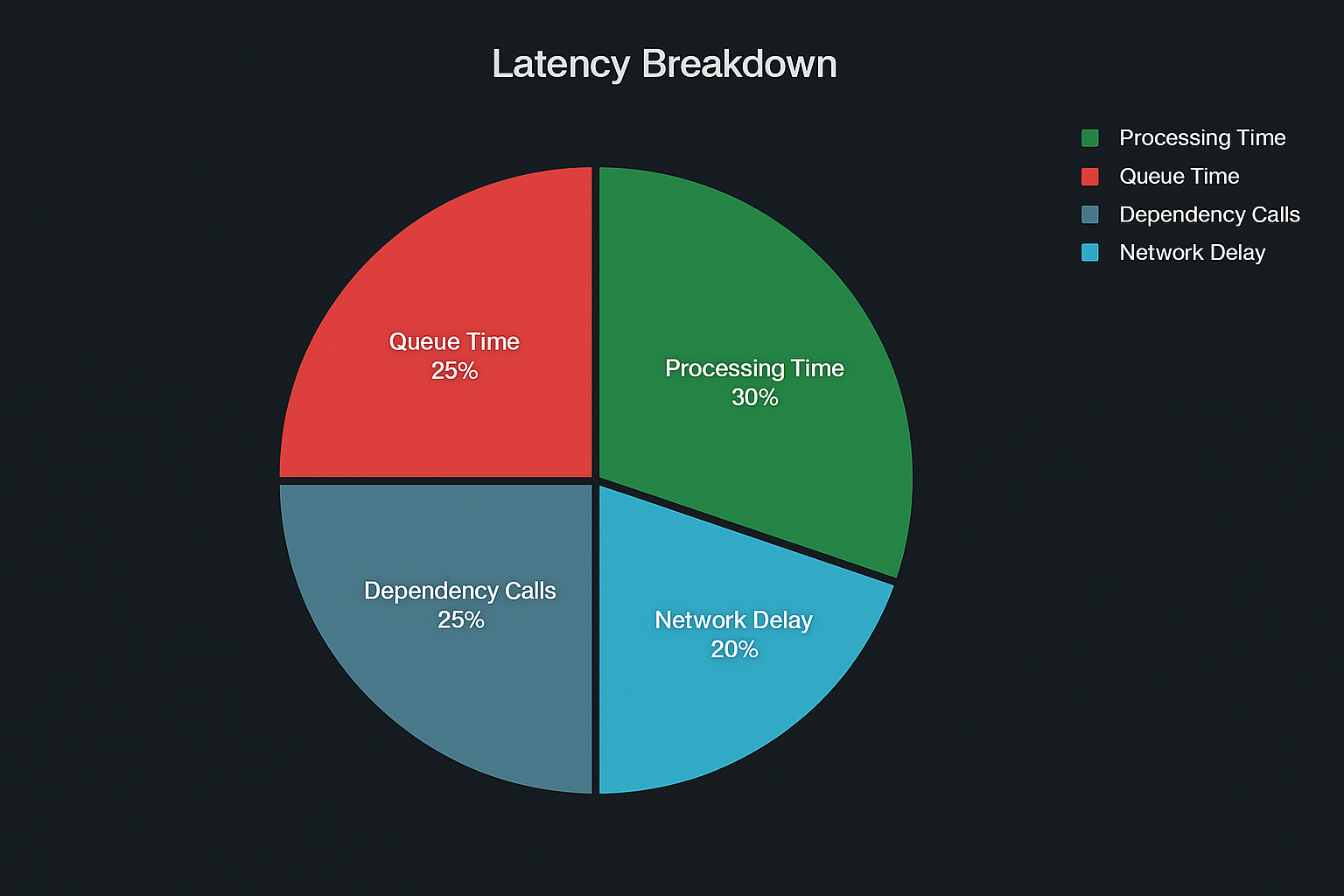
Best Practices to Tame API Latency
- Use Async/Non-blocking IO wherever possible.
- Batch Requests to minimize N+1 calls.
- Use Caching for repeatable data like product catalogs.
- Timeouts + Circuit Breakers (Hystrix, Resilience4j) to isolate failures.
- Deploy Near Users – Reduce cross-region network delays.
Final Thoughts
Microservices give us incredible flexibility—but with great decoupling comes great responsibility. Monitoring and optimizing API latency is critical to delivering snappy, reliable systems.
Bottlenecks aren’t always visible in code—they’re hidden in the wires between services.